自今我們已經介紹了樞紐分析來進行分組與分類,相關性可視化降低對於數據解讀的難度,學會了許多應用數據的方法,此外我們還有一種選擇是放棄特徵或是建立新特徵,畢竟在實際的資料集中,更有可能會有缺值的狀況發生,因此我們將討論特徵議題來優化整體數據分析。
為了 Demo 接下來的內容(欄目合併)可以先把剛剛 Kagle 中的 test.csv 內容下載進資料夾中
直接刪除無用欄目是一個很好的開始目標。通過放棄特徵,我們所需要處理的數據就更少了,這種方法簡單暴力,且能夠加快了我們筆記本的速度,減輕分析的難度。根據我們先前的假設,我想放棄Cabin 和 Ticket 特徵,我們可以利用以下方法來進行。
print("Before", train_df.shape, test_df.shape, combine[0].shape, combine[1].shape)
train_df = train_df.drop(['Ticket', 'Cabin'], axis=1)
test_df = test_df.drop(['Ticket', 'Cabin'], axis=1)
combine = [train_df, test_df]
print("After", train_df.shape, test_df.shape, combine[0].shape, combine[1].shape)
除了本身數據訓練集 (train) 要修正以外,測試集 (test) 我們在這次也一同做更動調整,最後輸出一個 combine 來合併兩個資料集。

創建新的特徵,從現有的特徵中提取,在放棄資料特徵之前,我們可以進一步拆解,分析 Name 特徵是否可以被設計來提取標題,我們可以使用正規表達式 (Regular Expression) 來提取標題特徵,匹配 Name 特徵中,以點字符結尾的第一個詞(\w+.)。
for dataset in combine:
dataset['Title'] = dataset.Name.str.extract(' ([A-Za-z]+)\.', expand=False)
pd.crosstab(train_df['Title'], train_df['Sex'])
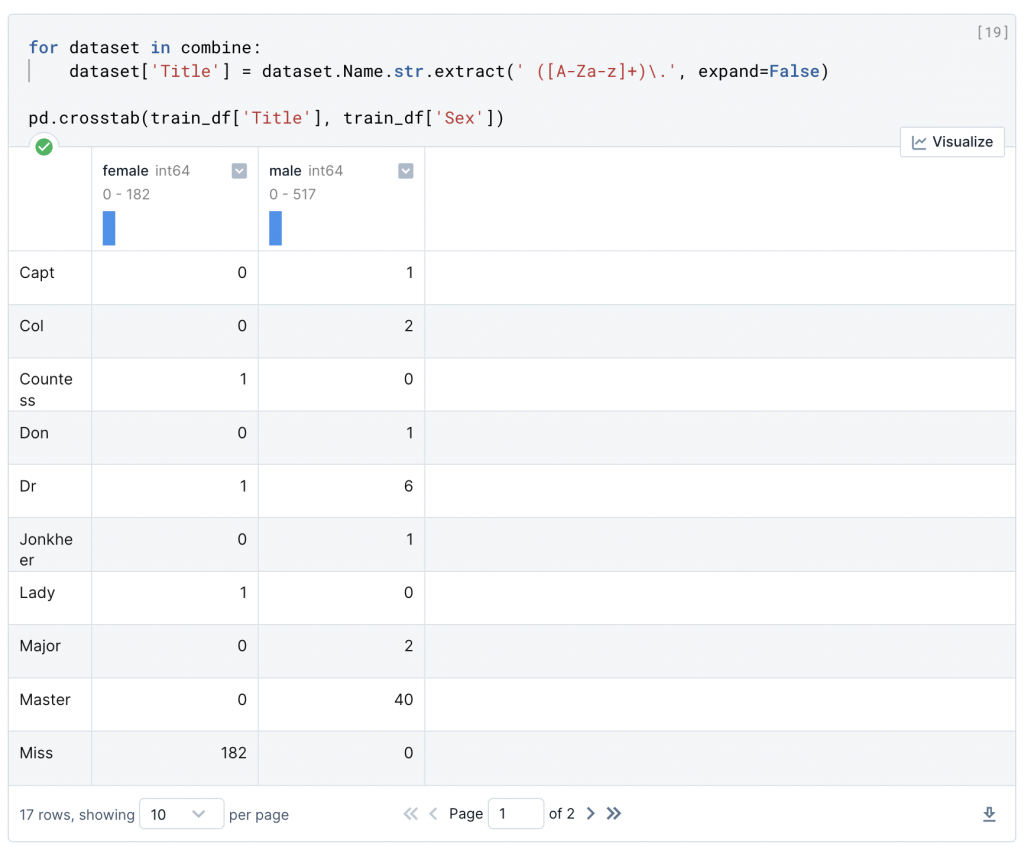
姓名的分類讓人感到眼花撩亂,但是只要能夠從中提取稱謂,從中創造新的特徵分類,那我們就能進行頭銜存活率的訓練。我們可以用一些更常見的名字,來取代一些稱謂。或者是我們可以直接歸類,這邊命名為 Rare。
for dataset in combine:
dataset['Title'] = dataset['Title'].replace(['Lady', 'Countess','Capt', 'Col',\
'Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare')
dataset['Title'] = dataset['Title'].replace('Mlle', 'Miss')
dataset['Title'] = dataset['Title'].replace('Ms', 'Miss')
dataset['Title'] = dataset['Title'].replace('Mme', 'Mrs')
train_df[['Title', 'Survived']].groupby(['Title'], as_index=False).mean()
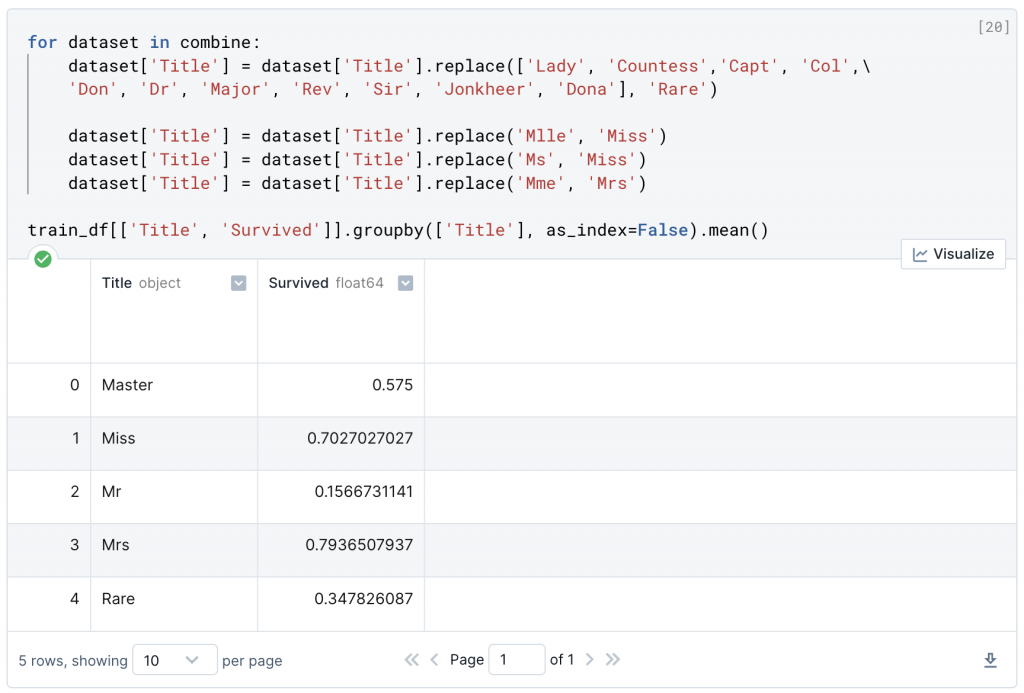
現在我們可以將包含字符串的特徵轉換為數值。這是大多數模型算法的要求。這樣做也會幫助我們實現特徵補全的目標。在上面我們總結出了 Master, Miss, Mr, Mrs, Rare 等四種不同的稱呼,可以再依照編號方式給予他們序列,將"Mr" 稱謂設定為 1, Miss 稱謂設定為 2 等等…( "Mrs": 3, "Master": 4, "Rare": 5),將原先字串列的內容轉化為序列。
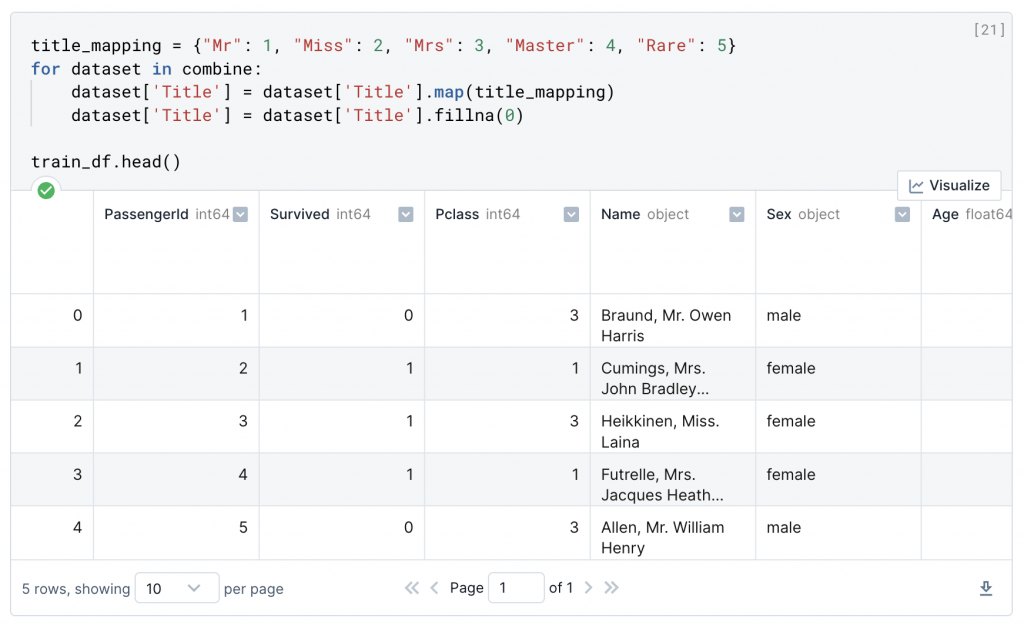
title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Rare": 5}
for dataset in combine:
dataset['Title'] = dataset['Title'].map(title_mapping)
dataset['Title'] = dataset['Title'].fillna(0)
train_df.head()
for dataset in combine:
dataset['Sex'] = dataset['Sex'].map( {'female': 1, 'male': 0} ).astype(int)
train_df.head()
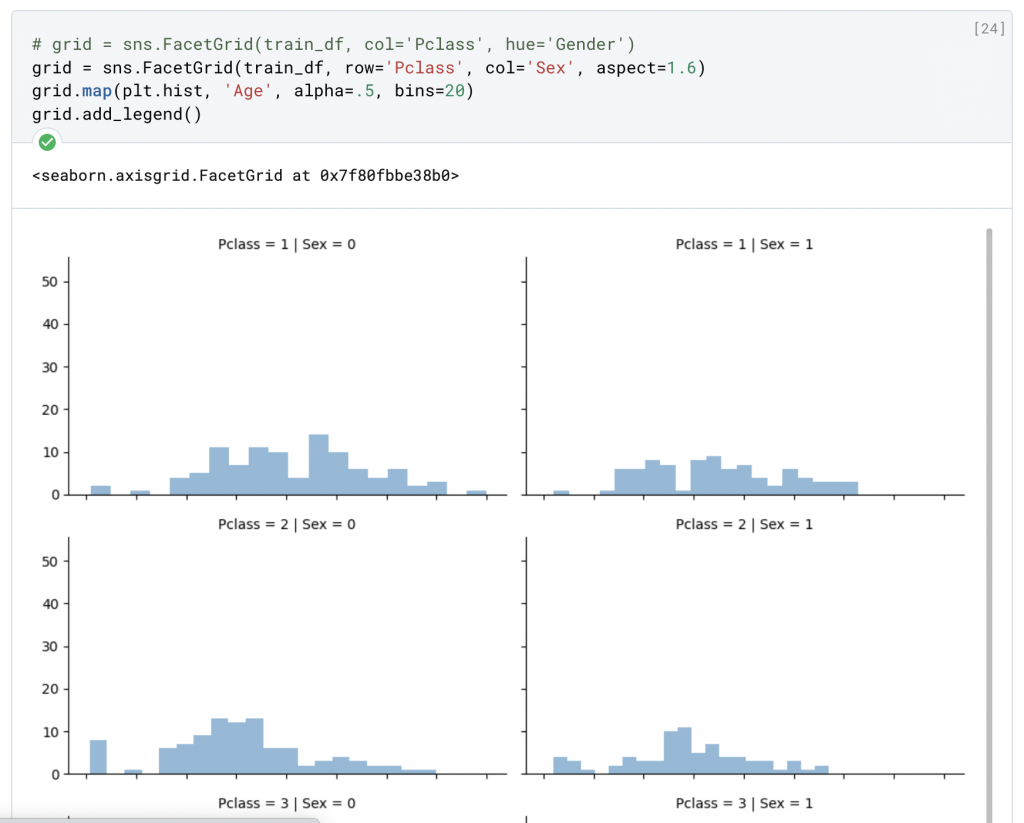
我們原先進行特徵判斷的時候有注意到 Age 有部分的缺失值,在這樣的情況下,為了避免運算與統計出現問題,我們要嘗試補齊這些缺失數值,我們一共有三種方法:
grid = sns.FacetGrid(train_df, row='Pclass', col='Sex', aspect=1.6)
grid.map(plt.hist, 'Age', alpha=.5, bins=20)
grid.add_legend()
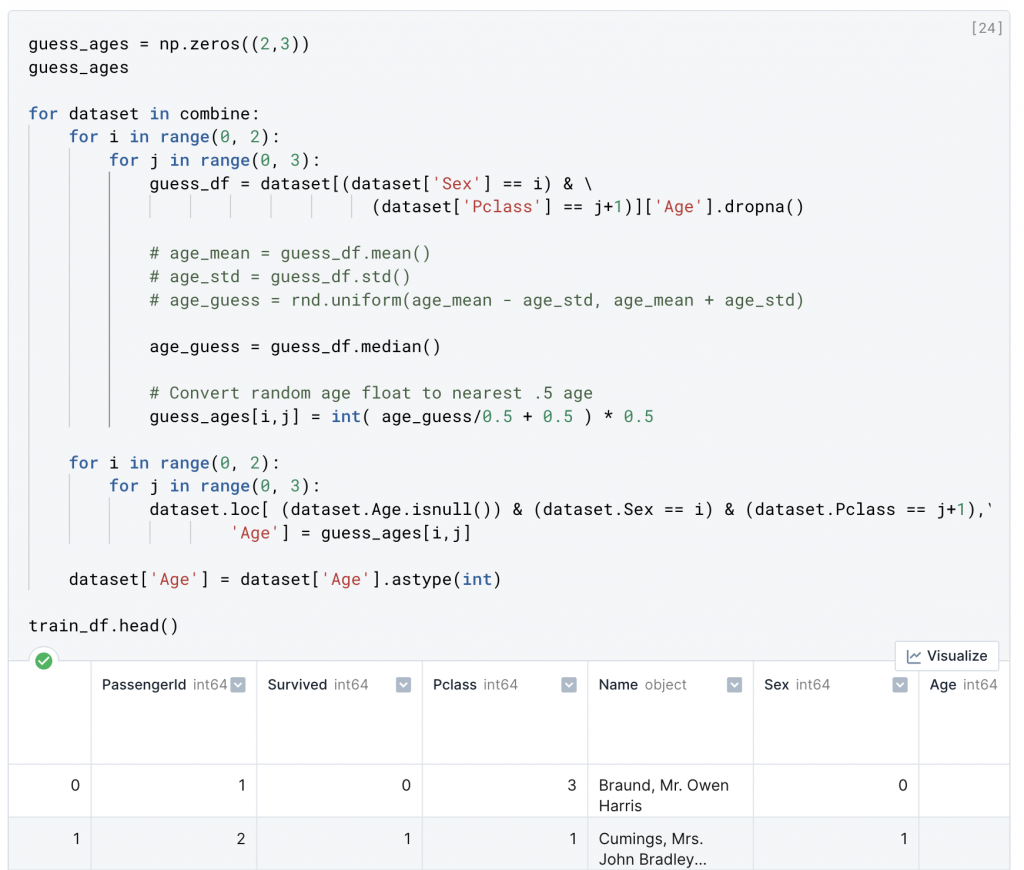
準備一個空集合開始進行特徵組合判斷,我們利用 SEX (0,1) 和 Pclass (1,2,3) 六種不同的組合還推斷年齡。完成數字連續特徵,在平均值和標準差之間生成隨機數。更準確的方法是使用其他相關的特徵。找出年齡、性別和 Pclass 之間的關聯性。使用 Pclass 和 Sex 特徵組合中的年齡中值來猜測年齡值。因此,Pclass=1 和 Gender=0 的年齡均值,Pclass=1 和 Gender=1 的年齡均值,以此類推。
guess_ages = np.zeros((2,3))
guess_ages
for dataset in combine:
for i in range(0, 2):
for j in range(0, 3):
guess_df = dataset[(dataset['Sex'] == i) & \
(dataset['Pclass'] == j+1)]['Age'].dropna()
age_guess = guess_df.median()
guess_ages[i,j] = int( age_guess/0.5 + 0.5 ) * 0.5
for i in range(0, 2):
for j in range(0, 3):
dataset.loc[ (dataset.Age.isnull()) & (dataset.Sex == i) & (dataset.Pclass == j+1),'Age'] = guess_ages[i,j]
dataset['Age'] = dataset['Age'].astype(int)
train_df.head()
創建年齡並確定與 Survived 的相關性,得出年齡區間與生存率的關係。
train_df['AgeBand'] = pd.cut(train_df['Age'], 5)
train_df[['AgeBand', 'Survived']].groupby(['AgeBand'],
as_index=False).mean().sort_values(by='AgeBand', ascending=True)
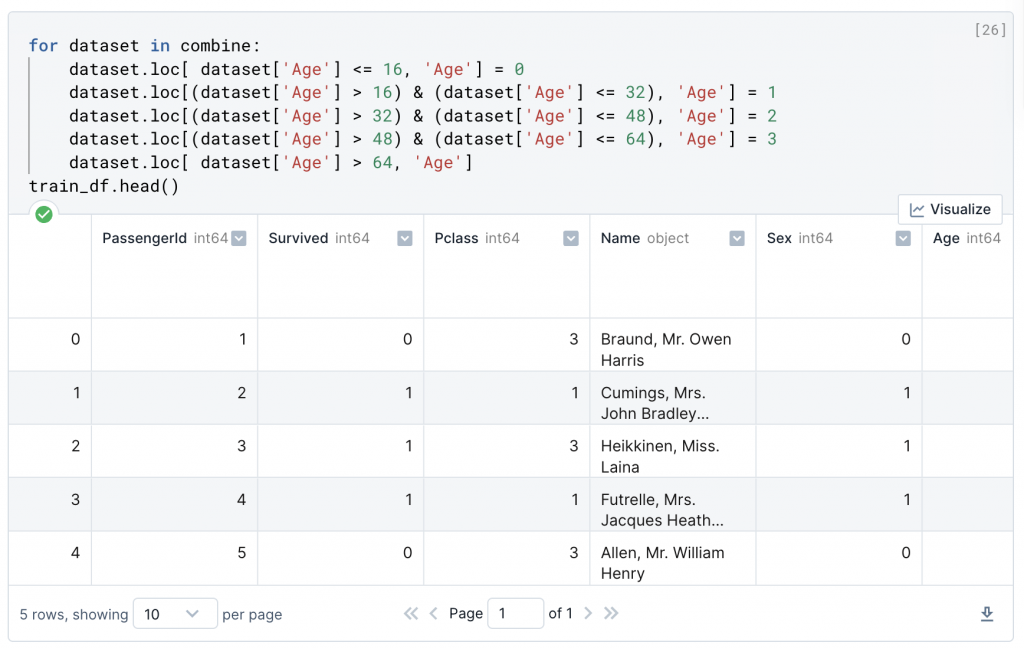
根據上方得出的年齡區間特徵,帶入至原資料內
年齡區間(-0.08, 16.0] 代表生存率為 0.55
年齡區間(16.0, 32.0]生存率為 0.3373737374
年齡區間(32.0, 48.0]生存率為 0.412037037
年齡區間(48.0, 64.0]生存率為 0.4347826087
年齡區間(64.0, 80.0]生存率為 0.09090909091
for dataset in combine:
dataset.loc[ dataset['Age'] <= 16, 'Age'] = 0
dataset.loc[(dataset['Age'] > 16) & (dataset['Age'] <= 32), 'Age'] = 1
dataset.loc[(dataset['Age'] > 32) & (dataset['Age'] <= 48), 'Age'] = 2
dataset.loc[(dataset['Age'] > 48) & (dataset['Age'] <= 64), 'Age'] = 3
dataset.loc[ dataset['Age'] > 64, 'Age']
train_df.head()
透過以上方式逐漸調整欄目內容,目標是將欄目逐漸變化將文字、序列都最簡單化,這樣可以幫助後續機器學習運算上的表現。這是本章最後一篇說明鐵達尼號資料集,雖然後續還有機器學習的內容,但不是我們本次「先別急著學 Python」中的重點,先別急著學 Python 最核心的目標在於說明做數據分析時,要如何階段性步驟地進行,並且善用選擇工具,比如說在小型乾淨數據集處理中,Excel 的實用性就有很大的機率大於 Python,你可以用樞紐分析來處理 Groupby,也可以快速的完成製圖。
今年沒組團,每一筆一字矢志不渝的獻身精神都是為歷史書寫下新頁,有空的話可以走走逛逛我們去年寫的文章。
Jerry 據說是個僅佔人口的 4% 人口的 INFP 理想主義者,總是從最壞的生活中尋找最好的一面,想方設法讓世界更好,內心的火焰和熱情可以光芒四射,畢業後把人生暫停了半年,緩下腳步的同時找了份跨領域工作。偶而散步、愛跟小動物玩耍。曾立過很多志,最近是希望當一個有夢想的人。
謝謝你的時間「訂閱,追蹤和留言」都是陪伴我走過 30 天鐵人賽的精神糧食。


 iThome鐵人賽
iThome鐵人賽